🔥DALL-E革命!120亿参数量下,零样本文本到图像生成如何突破性飞跃?🚀2.5B大挑战,Ope
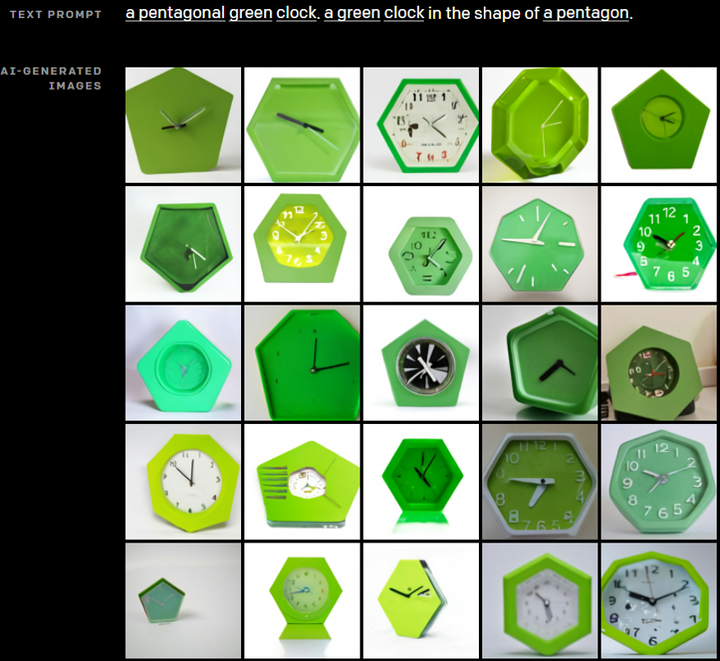
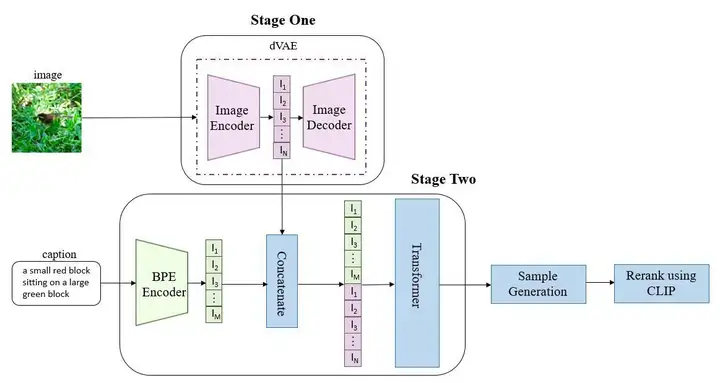
《零-shot文本-to-图像生成:DALL-E的革新之路》文章指出,从DRAW到GAN的发展展示了文本生成图像技术的进步,特别是零样本能力的实现。近年来,研究主要聚焦于模型优化和数据集扩展。CLIP、DDPM等代表作出现,但受限于数据量和参数规模。openAI提出Backbone为120亿参数量自回归transformer的大规模模型"DALL-E",通过两阶段训练,首先压缩图片并离散化特征,然后结合BPE将文本与图像编码输入Transformer,实现高效果零样本生成,显著超越前人。这一突破性工作标志着文本-to-image生成技术的新高峰。