一次了解所有功能!超详细【Stable Diffusion界面】大揭秘!
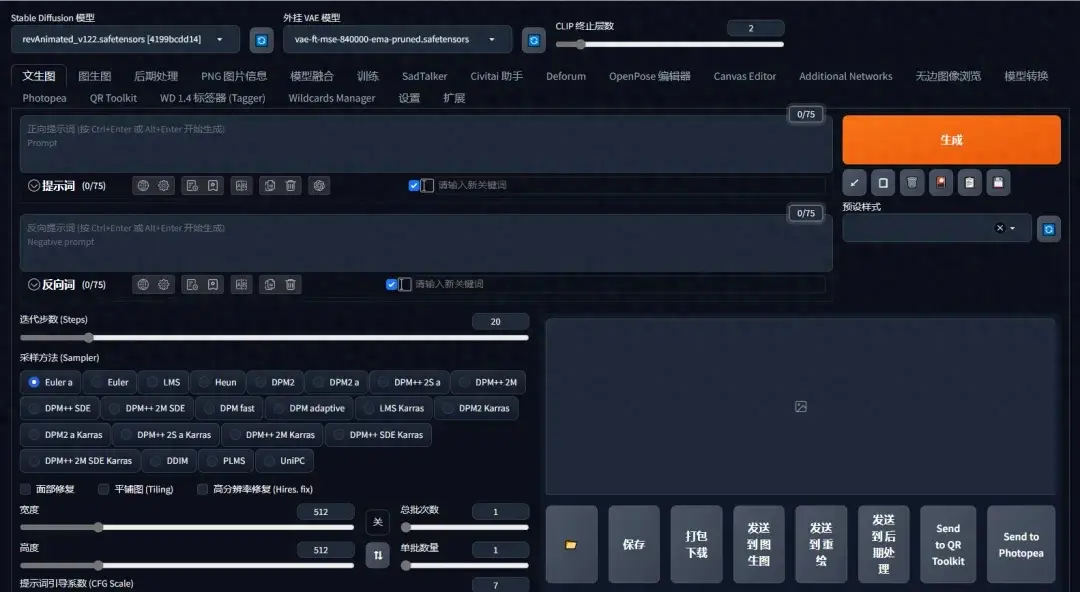
对于AI绘画的初学者而言,一看到SD的UI界面肯定是一脸懵,因为有太多陌生词汇,什么大模型、什么提示词、什么什么采样迭代,和传统的画图方式完全不在一个层面上,学习起来就无从下手~ 今天小元老师就给大家详细做一个介绍,一起来学吧~ 01、模型设定菜单栏 ①Stable Diffusion 模型:出图的基础,也叫底模、大模型,默认启动后是没有大模型的,有一些启动包可能里会送一两个,但是大部分还是需要自己去下载的。一般大模型文件后缀分为两种,一种是.ckpt,一种是.safetensors。大家可以将它理解为不同的“画师”,我们通过提示词描述我们的需求给这个“画师”,这个“画师”按自己的画风满足我们的要求。 ②外挂VAE模型:VAE是变分自编码器的英文缩写,主要作用是给画面去灰度,增加饱和度,类似滤镜的功能,如果有这个文件的话,画面颜色会更明亮艳丽,没有其实影响也不大,一般选择自动加载就好。 ③跳过CLIP层数:全称是语言与图片对比预训练,它是用来控制我们的关键词(prompt)和生成图片的关联性,这么理解:数值越高,关联越弱,SD发挥的越多,偏离我们想要的效果数值越低,关联越强,SD发挥的越少,接近我们想要的效果。它是一个成反比的关系,一般默认不动,数值保持为1就好。 02、提示词编辑栏 这里就是SD主要的输入界面了,虽然有一堆选项,但是我们真正用来出图的一般就是【文生图】和【图生图】两个选项,其他的都是一些辅助和设置。 ①提示词:输入的词语就是你想要的画面; ②反向提示词:输入词语就是你画面中不想出现的东西。 提示框内只能输入英文,所有符号都要使用英文半角,词语之间使用半角逗号隔开,句子也是可以的。 03、细节参数区 ①迭代步数:一般设定在20~30之间,主要取决于你的大模型。迭代步数越高,图片会越精致,越精确,但是消耗的时间也会相应增加。并不是越高越好,合适的才是最好的。 ②采样方法:代表不同的作画方式,这也是绘画零基础的人需要掌握的知识之一。SD提供了很多采样方法,给我们提供了多种场景的适配算法,每个采样方法都有它擅长的图像生成场景。 例如: · Euler a 适合生成相对简单的图像,适应于快速生成图像的场景,比如二次元的场景; · DPM++ 2M Karras、DPM++ SDE Karras 可以快速生成高品质图像,比如真人,自然场景的场景; · UniPC 可以生成更逼真的图像,并提高了采样速度,相当于你可以以更少的迭代步数实现更复杂精致的场景。主要适应与人形体相关的场景。 ③面部修复:适用于真人场景,主要是用来修复扭曲的人脸,例如当人物的脸在整个画布中占比很小时(全身画),不可避免的会模糊,面部修复可以将脸部局部放大进行修复,这样就可以使脸部精细化。 ④平铺图:可以实现图像的拼贴效果,适用于生成花纹的场景。 ⑤高分辨率修复:默认情况下,文生图在非常高的分辨率下(宽高大于756像素)制作图像,会出现比较混沌的图像,所以官方建议如果制作高分辨率的图像,打开该选项。 很吃显存,低配置用户不建议使用。放大算法用R-ESRGAN 4X+(真实三次元)或R-ESRGAN 4X+ Anime6B(动漫二次元)即可。 ⑥分辨率及单批数量:图片的长、宽,越大越吃显存。 ⑦提示词引导系数:系数越高,图片越贴合提示词;系数越低,AI自由发挥空间越大。一般设置在3~11,太高会破坏图像的结构和细节。 ⑧随机数种子:相当于每张图片生成的编号,如果在同一编号下生成图片,那么这些图片会在最大程度上保持相似度。“骰子”按钮代表随机,点击“循环”按钮则会固定值,使用相同的值,可以降低图像的随机性。 到这里,我们算是对SD有了一个简单的认识啦~


