出品|搜狐科技
作者|王一鸣
编辑|杨锦
“付费”已不再是普通用户想要绘画创作的拦路虎。
一直以来DALL-E、Midjourney和 Stable Diffusion这样的画图模型横扫设计界,效果惊艳,让许多网友惊呼将淘汰一波打工人。
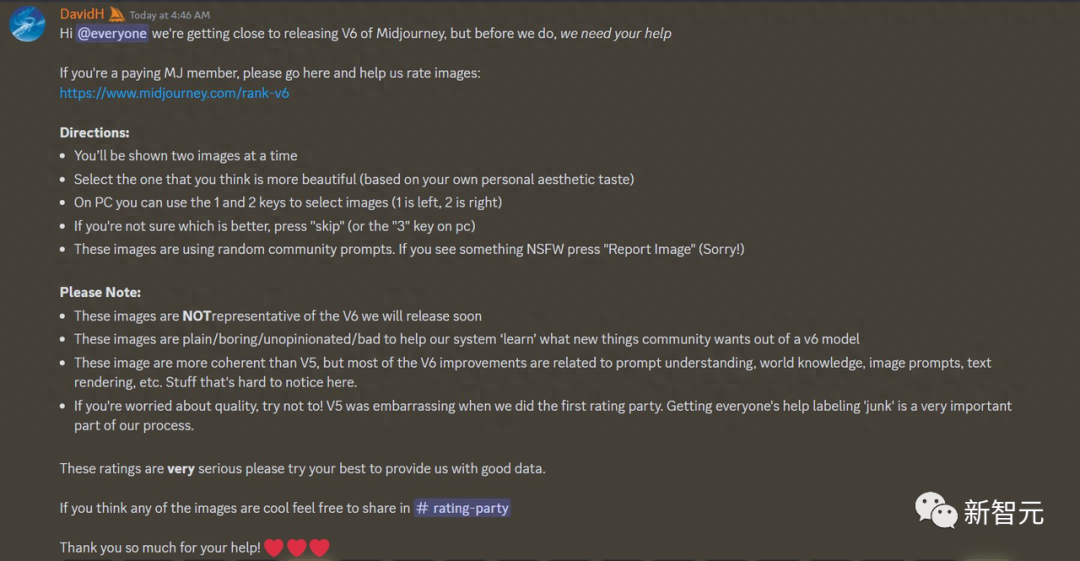
在此之前,AI图像生成器只能ChatGPT Plus付费用户独享,每个月需要20美元。现在ChatGPT的免费用户也可以使用DALL-E 3,每天生成最多两张图片。
其实ChatGPT氪金用户也只能每天生成50张,但是对于大部分人来说每天2张大概是足够的。
对比隔壁Midjourney,基础套餐就要每个月10美元,意思就是说不花钱,你一张图片都别想生成。
搜狐科技上手测试了几个案例,通过简单的几个提示词让DALL-E生成相应图像,涵盖多个不同类型,包含场景、插图、水彩画、古典艺术图和油画。
DALL-E熟悉各种艺术风格,可以根据文字描述来决定整幅图的元素和色彩基调。
1.我的婚礼规划师推荐婚礼现场使用新艺术风格,可不可以帮我预览一下大概的样子?

2.你做汇报幻灯片的时候想要一个体现“团队协作”的图?没问题。

3.生成一张有小柯基跟菠萝西瓜的极简水彩画。

DALL-E:超现实主义WALL-E机器人
DALL-E是目前市场上最强大的AI图像生成工具之一,由ChatGPT的OpenAI 开发。这个模型根据自然语言输入(提示)生成图像。也就是说,只要用户输入几个短语,它就能理解这些自然语言然后创作相应的图片。
很有意思的是,“DALL-E”这个名字是来自西班牙超现实主义艺术家萨尔瓦多达利(Salvador Dali)和皮克斯 (Pixar)的电影《WALL-E》的名字融合在一起而想出来的。

DALL-E可通过计算的方式进行图像的想象,为平面设计、图像样机、网站布局设计等行业提供了无尽的可能性。
4.生成一张20年之后城市大街上的景象的图片

5.DALL-E 3生成的中国风+西方文艺复兴风格的作品

DALL-E 3:插画是我的专业
DALL-E 3跟Midjourney等竞争对手的很大不同点就是,它生成的图像并不是“图片”。虽然很多人可能看不出这是人工智能生成的,但DALL-E生成的所有图片都像是插画或者图画。
也就是说通过一些指令可以生成体现艺术品的图片,而不是直接生成1:1复刻的影像结果。
同时,OpenAI有一项目的性很强的政策,他们表示希望减少“错误信息传播”。并且要求不可以生成“具有”任何特定艺术家风格的图像,或者是政治相关的内容。用户如果想生成类似这样的图片就会被ChatGPT告知 “我无法创建您请求的图像,因为它违反了内容政策”。

DALL-E历代回顾
DALL-E、DALL-E 2和DALL-E 3都有一个共性,它们都是深度学习(Deep Learning)技术开发的文本转图像模型,每个人都能用自然语言给出指令提示。当然了,它们之间也有略微不同,DALL-E 1代版本使用的GPT-3魔改版模型来生成图像。
具体来说,DALL-E 1代版本使用离散变分自动编码器 (dVAE) 技术,它是基于谷歌深度学习部门使用矢量量化变分自动编码器进行的研究。
2022年,OpenAI宣布了DALL-E下一代DALL-E 2,它能够将概念、属性和风格结合,从而生成更真实的高分辨率图像。
DALL-E 2改进了技术,这一代使用稳定的扩散模型生成更高质量的图像,模型集成了对比语言图像预训练 (CLIP) 模型的数据,它经过了4亿张带标签图像的训练。语言图像预训练模型借助评估提示语,从而决定生成恰当的图像,以辅助评估DALL-E的输出。
2023年9月,OpenAI官宣了DALL-E 3,并集成进了ChatGPT中。OpenAI团队表示,DALL-E 3可以捕获到更多细微差别和细节。所以说DALL-E 3模型能够更精准地依照复杂的提示词,生成细节更为丰富的图像。
DALL-E是怎么工作的?
输入“一只泰迪熊在时报广场上滑滑板”,可以得出以下图像:

DALL-E里指令文本语义和图像之间的联系,由对比CLIP(语言图像预训练)模型予以完成的。
CLIP是通过对数亿张图像(包括动物、人类、玩具等)进行针对性训练的,文本与图像会进行关联,提示工程会让模型学习两者之间的相关程度。
与其说CLIP分析文本来生成图像,不如说CLIP是通过分析文本与知识库中图像相关程度,然后做出判断再“创作”出的图像。CLIP从自然语言中学习语义的能力决定着 DALL-E模型的表现。
训练CLIP分为以下几个步骤:
1. 首先,所有图像及其相关标题都经过各自的编码器(编码器能够把文本转化为软件理解的参数),将所有对象映射到m维空间中(这是一个向量空间,m代表维度的数量,维度越高代表这个空间的复杂性)。
2. 然后对每个图像和文本计算相似度。
3. 训练目标需要最大化图片跟文本的相似度,让模型尽可能输出与文本相关的图像。


训练结束之后,CLIP模型就会被固定住,开始学习逆转图像编码映射。
然后再使用扩散模型GLIDE来翻转图像编码过程,这样可以让随机解码的CLIP图像进入生成内容。

一只柯基吹着小号的图片经过CLIP图像编码器,然后GLIDE通过此编码生成一张新图像,与此同时新图像保留了原始图像的显著特征。
DALL-E的目标不是重构原有图像,而是在原始图像的基础上生成一个全新的图像,但是原始图像主体的基本特征需要保留。
下一步,DALL-E需要把文本语义映射成相应的可视化对象。
最后——就是整合所有内容。
ChatGPT结合DALL-E为文字注入生命
DALL-E最大的特点就是跟ChatGPT进行集成,它直接构建在ChatGPT之上,用 ChatGPT来创建、拓展和优化指令。这样一来,用户无需在指令提示上花费太多时间。
当用户输入一个指令时,ChatGPT不仅能独处单词,还可以理解用户发出这个指令的意图和微妙含义。ChatGPT的强项就是能把抽象或复杂的想法转化为视觉元素,而DALL-E的图像生成模型恰好能够提供视觉素材库。
ChatGPT能够识别指令中潜在的错误或歧义。比如指令中会有前后逻辑错误或者语言混乱的情况。这时候模型就可以进行纠错,或者向用户提问去让指令变得更明确,以确保最终指令输入尽可能清晰和准确。
值得一提的是,ChatGPT 既能够完善、明确指令,又能协助用户实现更多创意。由于它通过大量的训练,所以能针对指令提出更具想象力的解释,突破图像生成的极限。
ChatGPT分析文字是它的强项,所以你可以讲一个故事:狗扮成海盗,带领着自己的船员打仗。头戴三角帽,手握手枪,海浪汹涌,而且还下着大雨,情况有些混乱。色彩阴暗而忧郁,而且不能确定他是否能活下来。
接着,你大脑里的故事就以图片的方式生动形象地展现了出来。
相比之下很多网友都表示要弃用Midjourney,因为它不能准确理解文本。
ChatGPT 推广了人类反馈强化学习的机器学习(RLHF)方法,这种方法通过人类的反馈来调整大语言模型的输出质量。为了DALL-E与ChatGPT无缝合成,OpenAI可以把RLHF的过程扩展到图像生成方面。
最重要的是它可以根据上下文来不停地调整生成内容。
比如一个警察有这么一个需求:给我画一个犯罪人物肖像,然后警察开始描述人物肖像特征。那这时候DALL-E应该怎么画?是要按照字面意思画出来,还是按照卡通形象画出来?正确是做法肯定是按照字面意思画出来,但模型未必知道。所以语言模型这时候可以通过反问的方式,来调整生成内容的风格。
作为人类会用很多方式来描述来期待不同的图像,所以ChatGPT在推理过程中会根据RLHF来判断人类最可能想要什么回答,然后生成相应的图像。利用指令不断补充要求和细节,让生成结果尽可能与用户需求相符。返回搜狐,查看更多
责任编辑: