文章主题:
在令人叹为观止方面,OpenAI 从不令人失望。

去年 1 月 6 日,OpenAI 发布了新模型 DALL·E,不用跨界也能从文本生成图像,打破了自然语言与视觉次元壁,引起了 AI 圈的一阵欢呼。
时隔一年多后,DALL·E 迎来了升级版本——DALL·E 2。

🎨✨DALL·E 2的进化!🔥相较于前任,它在画像生成的细腻度上有了飞跃提升,每像素都清晰可见,速度也快了节奏,延迟大大减少,用户体验直线上升!🎉不仅如此,新版本还解锁了对原图编辑的神奇能力,让创意无限可能,一图多变不再是梦!🎨💻
🎨✨OpenAI’s Groundbreaking AI Creation Tool, DALL·E 2, Unveiled但对于大众用户而言👀,默认的OpenAI大门并未完全敞开——DALL·E 2目前仅对研究者提供试用权限💡。想要一窥其卓越创意的力量,他们需要通过在线注册的方式先行体验。尽管如此,这股创新洪流已悄然开启,未来OpenAI有望将这一先进技术推向第三方应用领域,为全球开发者带来更多可能性🚀。记得持续关注,敬请期待未来的开放步伐!🌍💻
试玩 Waitlist 地址:https://labs.openai.com/waitlist
🎨✨DALL·E 2的科研力量震撼发布!🔍论文《Hierarchical Text-Conditional Image Generation with CLIP Latents》揭示了CLIP隐存的强大能效,由OpenAI的顶尖科学家团队 lidered by Prafulla Dhariwal 独立研发。🌍想象力不再受限于文字,只需一串描述,就能创造出令人惊叹的艺术品!🌟这革命性的技术正引领着生成式艺术的新篇章,让我们一起见证科技与创意的无缝融合!🌐#DALL·E2 #OpenAI #生成式艺术
论文地址:https://cdn.openai.com/papers/dall-e-2.pdf
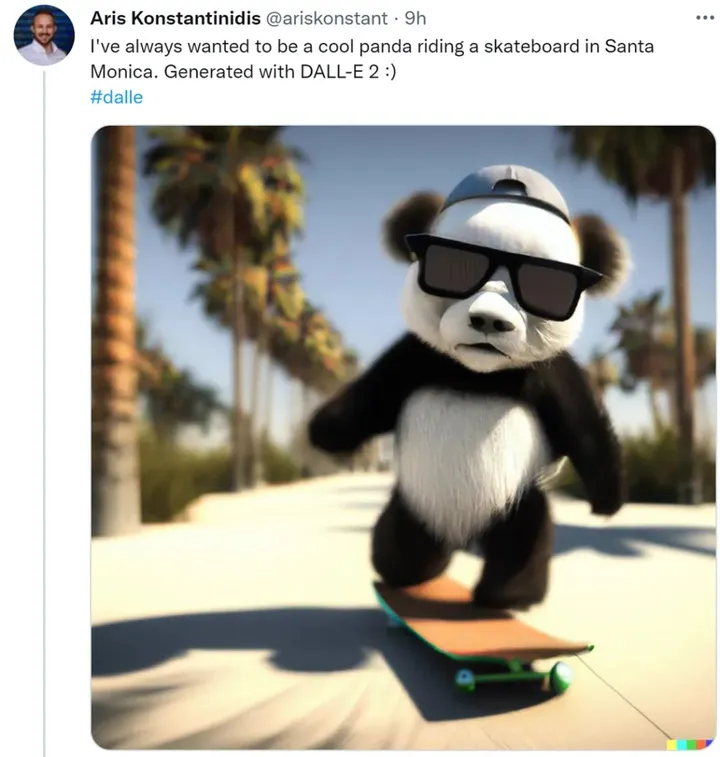
网友纷纷晒出了使用 DALL·E 2 生成的图像,比如玩滑板的熊猫靓仔。
又比如席地而坐看星空的小孩和小狗。

DALL·E 2 生成艺术大作
🎨✨DALL·E 2震撼登场!🔥👀它以卓越技艺将想象转化为现实,只需简单文本指令,就能绘制出惊人且细腻的图像。骑兵与宇宙英雄的奇妙融合,🚀 Türkas in星际驰骋,栩栩如生,令人惊叹不已!🌍不只是科幻梦,艺术创作的新里程碑!🎨不仅如此,DALL·E 2 的创新性在于其强大的概念融合和风格转换能力,能够自由组合元素,无论是古典还是现代,都能信手拈来。🎨brush in your mind’s eye, and DALL·E 2 paints it out for you! 💫想要一探究竟?赶快体验一下,让DALL·E 2带你开启视觉与艺术的奇妙之旅吧!🚀别忘了,这不仅仅是一款工具,它是创意无限的象征!✨SEO优化词汇:#DALL·E2创新展示#文本转图像#概念融合艺术#风格转换神器#探索视觉奇境

✨想象无限,创意无限!👀原来的照片不仅仅局限于一张,我们的技术实力在官网展示的10张精美实例中得到了充分展现。🚀不只是静态的画面,我们还能将奇思妙想转化为动态的艺术——比如那骑着马穿越星际的宇航员,每一帧都充满动感与科幻气息。🎨风格多变,变化无穷,每一张都是独一无二的故事。快来探索,释放你的创作热情吧!🎉

🎨🎨利用强大文本驱动的魔力,DALL·E 2 巧妙地重塑图像世界!它可以对图片进行细腻的编辑操作,从光影交织到纹理细节,每一步都精准无误。👀想象一下,左边是基础画布,右边则是经过魔法触碰后的生动展现——数字1、2、3悄悄化身为元素,等待你的指令赋予生命。只需轻轻一点,在1的位置,柯基犬跃然而出,瞬间点亮画面!🎉现在,让我们一起探索这创意与科技交织的奇妙世界吧!#DALL·E2 #图像编辑 #创意无限

你也可以在 3 处添加一只柯基犬。

DALL·E 2 可以根据原图像进行二次创作,创造出不同的变体:

你可能会问,DALL·E 2 比一代模型到底好在哪?简单来说 DALL·E 2 以 4 倍的分辨率生成更逼真、更准确的图像。例如下图生成一幅「日出时坐在田野里的狐狸,生成的图像为莫奈风格。」DALL·E 2 生成的图像更准确。

看完上述展示,我们可以将 DALL·E 2 的特点归结如下:DALL·E 2 的一项新功能是修复,在 DALL·E 1 的基础上,将文本到图像生成应用在图像更细粒度的级别上。用户可以从现有的图片开始,选择一个区域,让模型对图像进行编辑,例如,你可以在客厅的墙上画一幅画,然后用另一幅画代替它,又或者在咖啡桌上放一瓶花。该模型可以填充 (或删除) 对象,同时考虑房间中阴影的方向等细节。
DALL·E 2 的另一个功能是生成图像不同变体,用户上传一张图像,然后模型创建出一系列类似的变体。此外,DALL·E 2 还可以混合两张图片,生成包含这两种元素的图片。其生成的图像为 1024 x 1024 像素,大大超过了 256 x 256 像素。
生成模型的迭代
DALL·E 2 建立在 CLIP 之上,OpenAI 研究科学家 Prafulla Dhariwal 说:「DALL·E 1 只是从语言中提取了 GPT-3 的方法并将其应用于生成图像:将图像压缩成一系列单词,并且学会了预测接下来会发生什么。」
这是许多文本 AI 应用程序使用的 GPT 模型。但单词匹配并不一定能符合人们的预期,而且预测过程限制了图像的真实性。CLIP 旨在以人类的方式查看图像并总结其内容,OpenAI 迭代创建了一个 CLIP 的倒置版本——「unCLIP」,它能从描述生成图像,而 DALL·E 2 使用称为扩散(diffusion)的过程生成图像。
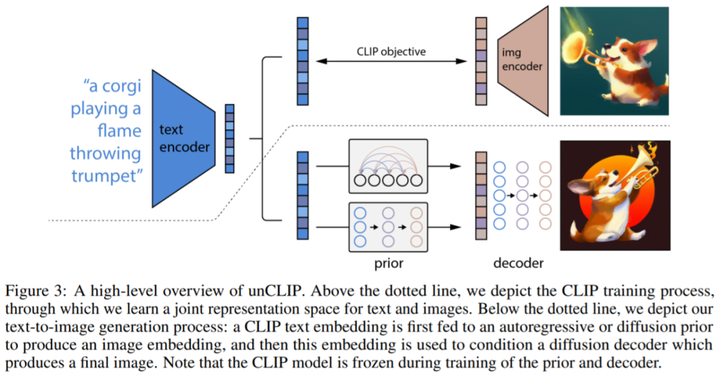
训练数据集由图像 x 及其对应的字幕 y 对 (x, y) 组成。给定图像 x, z_i 和 z_t 分别表示 CLIP 图像和文本嵌入。OpenAI 生成堆栈以使用两个组件从字幕生成图像:
先验 P(z_i |y) 生成以字幕 y 为条件的 CLIP 图像嵌入 z_i;解码器 P(x|z_i , y) 以 CLIP 图像嵌入 z_i(以及可选的文本字幕 y)为条件生成图像 x。解码器允许研究者在给定 CLIP 图像嵌入的情况下反演图像(invert images),而先验允许学习图像嵌入本身的生成模型。堆叠这两个组件产生一个图像 x 、给定字幕 y 的生成模型 P(x|y) :
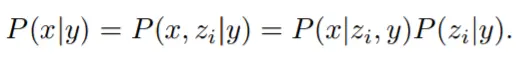
DALL·E 的完整模型从未公开发布,但其他开发人员在过去一年中已经构建了一些模仿 DALL·E 功能的工具。最受欢迎的主流应用程序之一是 Wombo 的 Dream 移动应用程序,它能够根据用户描述的各种内容生成图片。

OpenAI 已经采取了一些内置的保护措施。该模型是在已剔除不良数据的数据集上进行训练的,理想情况下会限制其产生令人反感的内容的能力。
为避免生成的图片被滥用,DALL·E 2 在生成的图片上都标有水印,以表明该作品是 AI 生成的。此外,该模型也无法根据名称生成任何可识别的面孔。
DALL·E 2 将由经过审查的合作伙伴进行测试,但有一些要求:禁止用户上传或生成「可能造成伤害」的图像。他们还必须说明用 AI 生成图像的作用,并且不能通过应用程序或网站将生成的图像提供给其他人。
但 OpenAI 希望稍后再将 DALL·E 2 其添加到该组织的 API 工具集中,使其能够为第三方应用程序提供支持。Dhariwal 说:「我们希望分阶段进行这个过程,以从获得的反馈中不断评估如何安全地发布这项技术。」
参考链接:
https://www.theverge.com/2022/4/6/23012123/openai-clip-dalle-2-ai-text-to-image-generator-testing

AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!

