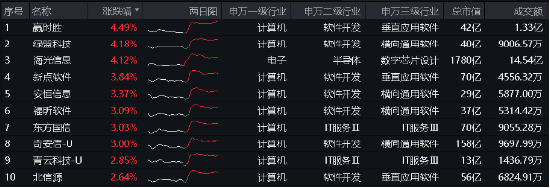
文章主题:
Sora 是一个 AI 模型,可以根据文本指令创建现实且富有想象力的场景。
下面展示了训练过程中具有固定种子和输入的视频样本的比较。随着训练计算(基础计算、4倍计算、32倍计算)的增加,样本质量显著提高。
可变的持续时间、分辨率、宽高比
过去的图像和视频生成方法通常会将视频调整大小、裁剪或修剪为标准尺寸,例如,分辨率为 256×256 的 4 秒视频。我们发现,对原始大小的数据进行训练有几个好处。
采样灵活性
Sora 可以采样宽屏 1920x1080p 视频、垂直 1080×1920 视频以及介于两者之间的所有视频。这使得 Sora 可以直接以其原生宽高比为不同设备创建内容。它还使我们能够在以全分辨率生成之前快速以较低尺寸制作原型内容 – 所有这些都使用相同的模型。
改进的框架和构图
我们根据经验发现,以原始长宽比对视频进行训练可以改善构图和取景。我们将 Sora 与将所有训练视频裁剪为正方形的模型版本进行比较,这是训练生成模型时的常见做法。在方形作物(左)上训练的模型有时会生成仅部分可见主体的视频。相比之下,Sora(右)的视频的取景效果有所改善。
语言理解
训练文本到视频生成系统需要大量带有相应文本字幕的视频。我们应用了 DALL·E 3 中引入的重新字幕技术30到视频。我们首先训练一个高度描述性的字幕生成器模型,然后使用它为训练集中的所有视频生成文本字幕。我们发现,对高度描述性视频字幕进行训练可以提高文本保真度以及视频的整体质量。
与 DALL·E 3 类似,我们还利用 GPT 将简短的用户提示转换为较长的详细字幕,然后发送到视频模型。这使得 Sora 能够生成准确遵循用户提示的高质量视频。
(一个女人 穿着 绿色连衣裙和遮阳帽


AI时代,拥有个人微信机器人AI助手!AI时代不落人后!
免费ChatGPT问答,办公、写作、生活好得力助手!
搜索微信号aigc666aigc999或上边扫码,即可拥有个人AI助手!